What is Slurm?¶
Slurm is a system that helps manage and run jobs on a group of computer nodes called a cluster. It makes sure that the right jobs are running on the right computers at the right time.
Slurm has three main purposes:
- Allocates exclusive and/or non-exclusive access to resources (compute nodes) to users for some duration of time so they can perform work;
- Provides a framework for starting, executing, and monitoring work (normally a parallel job) on the set of allocated nodes;
- Arbitrates contention for resources by managing a queue of pending work;
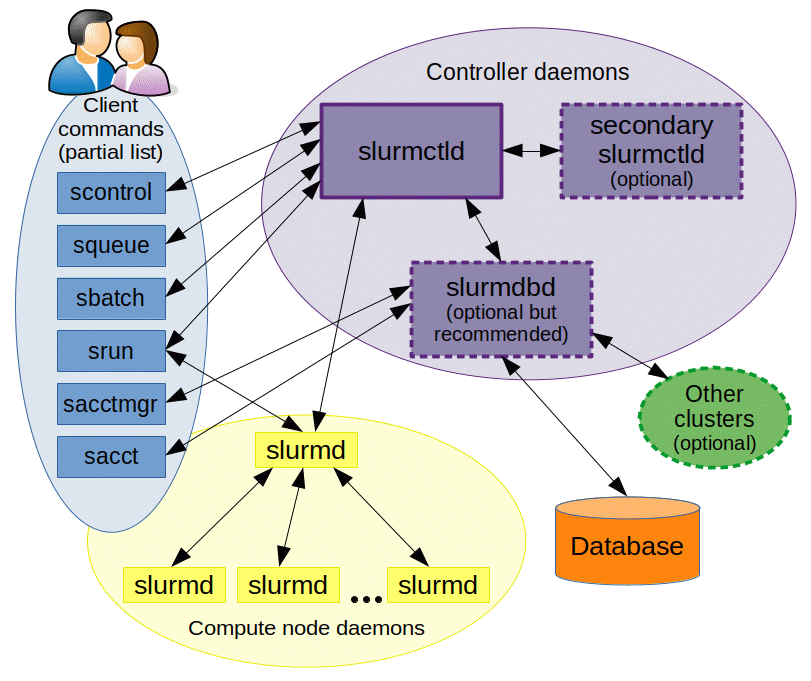
Slurm's internal structure¶
Slurm consists of a set of daemons:
- The slurmctld daemon, a centralized manager to monitor resources and work. There may also be a backup manager to assume those responsibilities in the event of failure;
- The slurmd daemon running on each compute node, which provide fault-tolerant hierarchical communications and lets users interact with the cluster. Basically: it waits for work, executes that work, returns status, and waits for more work;
- The optional slurmdbd daemon, which can be used to record accounting information for multiple Slurm-managed clusters in a single database;
- The optional slurmrestd daemon which can be used to interact with Slurm through its REST API.
List of Slurm commands¶
All Slurm commands start with s:
-
sacctis used to report job or job step accounting information about active or completed jobs. -
sallocis used to allocate resources for a job in real time. Typically this is used to allocate resources and spawn a shell. The shell is then used to execute srun commands to launch parallel tasks. -
sattachis used to attach standard input, output, and error plus signal capabilities to a currently running job or job step. One can attach to and detach from jobs multiple times. -
sbatchis used to submit a job script for later execution. The script will typically contain one or more srun commands to launch parallel tasks. -
sbcastis used to transfer a file from local disk to local disk on the nodes allocated to a job. This can be used to effectively use diskless compute nodes or provide improved performance relative to a shared file system. -
scancelis used to cancel a pending or running job or job step. It can also be used to send an arbitrary signal to all processes associated with a running job or job step. -
scontrolis the administrative tool used to view and/or modify Slurm state. Note that many scontrol commands can only be executed as user root. -
sinforeports the state of partitions and nodes managed by Slurm. It has a wide variety of filtering, sorting, and formatting options. -
spriois used to display a detailed view of the components affecting a job's priority. -
squeuereports the state of jobs or job steps. It has a wide variety of filtering, sorting, and formatting options. By default, it reports the running jobs in priority order and then the pending jobs in priority order. -
srunis used to submit a job for execution or initiate job steps in real time. srun has a wide variety of options to specify resource requirements, including: minimum and maximum node count, processor count, specific nodes to use or not use, and specific node characteristics (so much memory, disk space, certain required features, etc.). A job can contain multiple job steps executing sequentially or in parallel on independent or shared resources within the job's node allocation. -
ssharedisplays detailed information about fairshare usage on the cluster. Note that this is only viable when using the priority/multifactor plugin. -
sstatis used to get information about the resources utilized by a running job or job step. -
striggeris used to set, get or view event triggers. Event triggers include things such as nodes going down or jobs approaching their time limit. -
sviewis a graphical user interface to get and update state information for jobs, partitions, and nodes managed by Slurm.
Common interactions¶
In this page we'll list some common Slurm interactions to run, cancel or monitor jobs.
Monitoring¶
Monitoring the status of cluster's nodes¶
The command sinfo can be used to monitor the state of each node, including partitions, time limits, state, and names of the nodes in that partition:
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
admin up infinite 1 idle node121
department_only up 3-00:00:00 3 mix node[132-133,135]
department_only up 3-00:00:00 18 idle node[103,112-114,116,120,123-124,126,130,134,137-143]
multicore up 6:00:00 2 idle node[106-107]
students* up 1-00:00:00 11 idle node[108-111,122,145-149,151]
Node states
For a full list of the meaning of each state, refer to Slurm's official docs. Some of the common states are:
*: the node is presently not responding and will not be allocated any new work;ALLOCATED: the node has been allocated to one or more jobs;- {
DOWN,DRAINED,FAIL,INVAL}: the node is unavailable for use. Slurm can automatically place nodes in this state if some failure occurs, so inform an admin ASAP; DRAINING: the node is currently allocated a job, but will not be allocated additional jobs;- {
IDLE,MIXED}: the node is not allocated to any jobs and is available for use; UNKNOWN: the Slurm controller has just started and the node's state has not yet been determined.
Monitoring the status of jobs¶
The command squeue can be used to view information about jobs located in the Slurm scheduling queue, including job ID, partition, name, user, state, execution time, node name:
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
326 debug sleep guest R 0:03 1 node123
Job states
The ST column shows the states of the jobs. For a full list of the meaning of each state, refer to Slurm's official docs.
Some of the common states are:
- {
BF,F,NF,PR}: the job has failed to launch or complete; OOM: the job experienced out of memory error;R: the job is running;CG: the job is in the process of completing. Some processes on some nodes may still be active.
Submitting jobs¶
Submitting a non-interactive job¶
A non-interactive job can be run using srun <commands>.
You have to remember to use the -p or --partition flag, alongside the requirements of the job.
A job with no requirements can be run without further arguments:
$ srun -p <partition> bash -c "echo 'It works! My name is:'; hostname"
It works! My name is:
node116
A job with certain requirements needs all necessary resources to be specified:
$ srun -p <partition> --gpus=2 bash -c "echo 'It works! Here is a summary of my GPUs:'; nvidia-smi"
It works! Here is a brief of my GPUs:
Tue Mar 11 16:13:07 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.86.16 Driver Version: 570.86.16 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Quadro RTX 6000 Off | 00000000:41:00.0 Off | 0 |
| N/A 27C P8 20W / 250W | 1MiB / 23040MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 Quadro RTX 6000 Off | 00000000:C1:00.0 Off | 0 |
| N/A 25C P8 13W / 250W | 1MiB / 23040MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
Read Slurm's official docs for a list of all the available flags. Some common requirements are the following:
--gpus: the minimum number of GPUs the node must have to run the job;--mem: the real memory required per node, in MBs;
Submit a non-interactive container¶
You can do it using Singularity.
An interactive job can be run using srun singularity run <container_path> <commands>.
In this example, the hostname command will be executed into the pytorch container run on a node:
$ srun singularity run docker://pytorch/pytorch:2.6.0-cuda12.6-cudnn9-devel hostname
INFO: Using cached SIF image
==========
== CUDA ==
==========
CUDA Version 12.6.3
Container image Copyright (c) 2016-2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
A copy of this license is made available in this container at /NGC-DL-CONTAINER-LICENSE for your convenience.
WARNING: The NVIDIA Driver was not detected. GPU functionality will not be available.
Use the NVIDIA Container Toolkit to start this container with GPU support; see
https://docs.nvidia.com/datacenter/cloud-native/ .
node111
Submitting an interactive container¶
You can do it using Singularity.
An interactive job can be run using srun --pty singularity shell <container_path>, where the --pty flag spawns a pseudo-terminal.
In this example, the pytorch container will be executed on a node with 2 GPUs.
The --nv flag tells Singularity to mount the GPUs:
$ srun --gpus=2 --pty singularity shell --nv docker://pytorch/pytorch:2.6.0-cuda12.6-cudnn9-devel
INFO: Using cached SIF image
Singularity> nvidia-smi
Wed Mar 19 16:15:07 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.124.06 Driver Version: 570.124.06 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 Quadro RTX 6000 Off | 00000000:41:00.0 Off | 0 |
| N/A 29C P0 54W / 250W | 1MiB / 23040MiB | 3% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 Quadro RTX 6000 Off | 00000000:C1:00.0 Off | 0 |
| N/A 29C P0 56W / 250W | 1MiB / 23040MiB | 4% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
Singularity>
Deleting jobs¶
Deleting a job by its job ID¶
A particular job can be canceled using the scancel <job_id> command:
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
326 debug sleep debug R 0:03 1 node123
$ scancel 326
$ squeue
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
Deleting all the jobs of a user¶
All the jobs of a user can be canceled using the -u or --user flag, by typing scancel --user <user_id> command: